The IMMERSE Training Fellowship is a one-year fellowship experience aimed at supporting education researchers to integrate mixture modeling to address critical research questions. Generally funded by the Institute of Education Studies (IES; R305B220021), selected fellows will receive in-depth training on how to use mixture models as well as one year of continued support to ensure fellows feel supported while engaging in their own research using mixture models.
Timeline Information
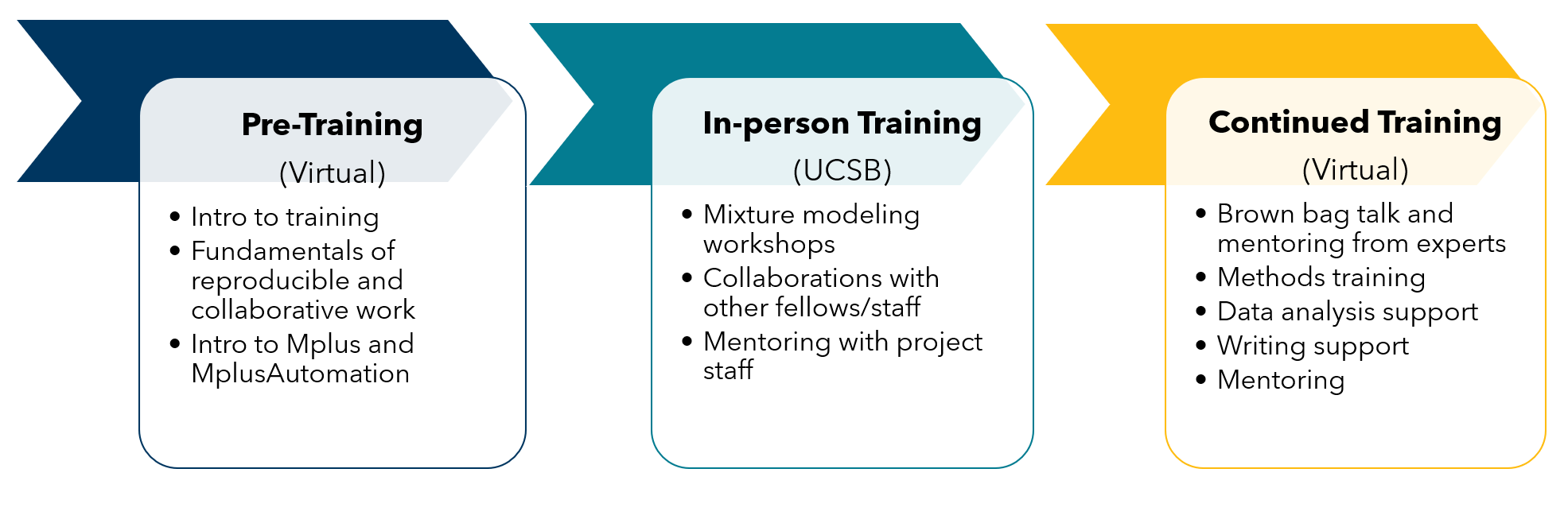
The objective is to introduce the program and lay a foundation for a collaborative, reproducible data science foundation which will serve them throughout the year-long training.
Fellows will build essential skills that require researchers to work together, using workflows and tools that facilitate computational reproducibility, project management, and collaboration. Researchers with domain expertise often lack formal training in data science, which can lead to non-reproducible analyses that lack clear organization and documentation, as well as a poor system for sharing and reviewing code with others. In pre-training workshops, fellows will build essential skills and good practices for working with data (e.g. how to store and organize datasets), organizing projects and building reproducible workflows, exploring and analyzing data (e.g., in scripted code and/or R Markdown), and collaborating and managing projects with git and GitHub.
The in-person training is held at UCSB. Fellows will stay at The Club, a hotel on the campus of UCSB. The in-person training will be led by Drs. Karen Nylund-Gibson and Katherine Masyn. UCSB graduate students will lead hands-on lab sessions.
After the initial training at UCSB, participants will be engaged in continued training throughout the year. This will be in continued methods training, mentoring meetings with project staff, brown bag talks, consulting on statistical analysis from graduate students, and one-on-one mentoring from experts in their identified field.
Brown-bag Talks/Mentoring Sessions. These talks will be held virtually. They will include talks from identified consultants who will give a talk on a project in their respective area that used mixture modeling and how they think the models could be used for future work. Any fellows who are in their related area will also have an opportunity to network and consult with these individuals (see letters of support), providing feedback on their ideas and projects. For example, Dr. Danielle Harlow, is a science educator who has used admixture modeling in research programs, will give a brown-bag talk on her research using mixtures models and will be available to consult with fellows interested in science education.
Methods Training. While the pre- and in-person workshops will have provided the foundational knowledge and resources to run models, continued methods training will be provided throughout the training year, taught by the Drs. Nylund-Gibson, Maysn, and Ing. Topics may include advanced covariate/distal outcome, graphical presentation of results, using GitHub for effective collaborations, and the presentation of new modeling developments. These will be both synchronous and asynchronous resources, depending on the month and will be available to fellows when they are ready to access them.
Ongoing Virtual Consulting. Recognizing the importance of ongoing support throughout the analysis process, we will provide one year of support to facilitate the use of the modeling in their own research. This includes meeting one-on-one with the leadership team (including graduate students) to discuss research questions, support with data management and coding questions, or troubleshoot data problems dealing with their own data. Each month, there will be “office hours” that the fellows can sign up for. These online meetings will be with project personnel (Nylund-Gibson, Masyn, or Ing) or the graduate students. Depending on the needs of the fellow in a given month, they can decide what office hours to sign up for, and once signed up the nature of what is discussed at the office hours. For example, an office hour with a graduate student may help with data coding and merging data files and an office hour with Dr. Nylund-Gibson could include conceptualizing the larger model or to talk through modeling results. While each fellow will have a primary mentor from project staff, they are able to meet with any available project staff.